

Hallucinations from large language models (LLMs) aren’t just amusing glitches; in a business context, they can spell serious risk. When generative AI (GenAI) produces false or misleading outputs, enterprises face potential legal exposure, reputational harm, and compliance failures. This issue has leapt into prominence recently: 92% of Fortune 500 companies now use ChatGPT or similar AI tools, embedding them into operations. With such widespread adoption, the stakes are higher than ever. In fact, a recent global survey found AI “hallucinations” top the list of generative AI concerns for over a third of business leaders. Simply put, mitigating LLM hallucinations and false outputs has become a critical priority from an enterprise perspective.
Unfortunately, much of the guidance on this problem is either highly academic or scattered across niche blogs. That leaves organisations piecing together advice on their own. This comprehensive guide fills that gap, offering a practical, enterprise-focused look at why AI hallucinations matter now, the real-world risks they pose, and proven strategies to prevent these false outputs. We’ll also highlight common mistakes to avoid. By the end, you’ll understand why taming AI hallucinations isn’t just about model quality. It’s about protecting your business.
Why AI Hallucinations Matter Now

GenAI is everywhere. Businesses large and small are deploying LLMs in customer service, marketing content, analytics, and more. This rapid uptake brings immense benefits but also new risks. When an AI confidently states a false “fact” or makes up an answer, the fallout can be very real. Recent news headlines underscore the point.
For example, in 2023, a New York lawyer unknowingly submitted a court brief full of fake case citations generated by ChatGPT, an error that led to sanctions and a $5,000 fine. In another case, Air Canada’s customer service chatbot gave a passenger inaccurate information about ticket refunds, and the airline was later forced by a tribunal to honour a refund policy that the bot had entirely fabricated. These incidents illustrate why now is the time to take AI hallucinations seriously.
It’s not just isolated anecdotes, either. Industry surveys and experts are sounding the alarm. One insurance risk report notes that AI hallucinations can lead to financial harm, legal problems, regulatory sanctions, and damage to trust and reputation, all rippling out to customers and partners. In high-stakes fields like finance or healthcare, a single fabricated answer could mean compliance violations or even lives at risk. Even in day-to-day business, an LLM’s plausible-sounding false output might cause employees to make poor decisions or mislead customers, eroding confidence in your brand. In short, hallucinations are not just an academic quirk of AI; they’re a real-world business risk that demands mitigation.
Industry Trends and Real-World Risks
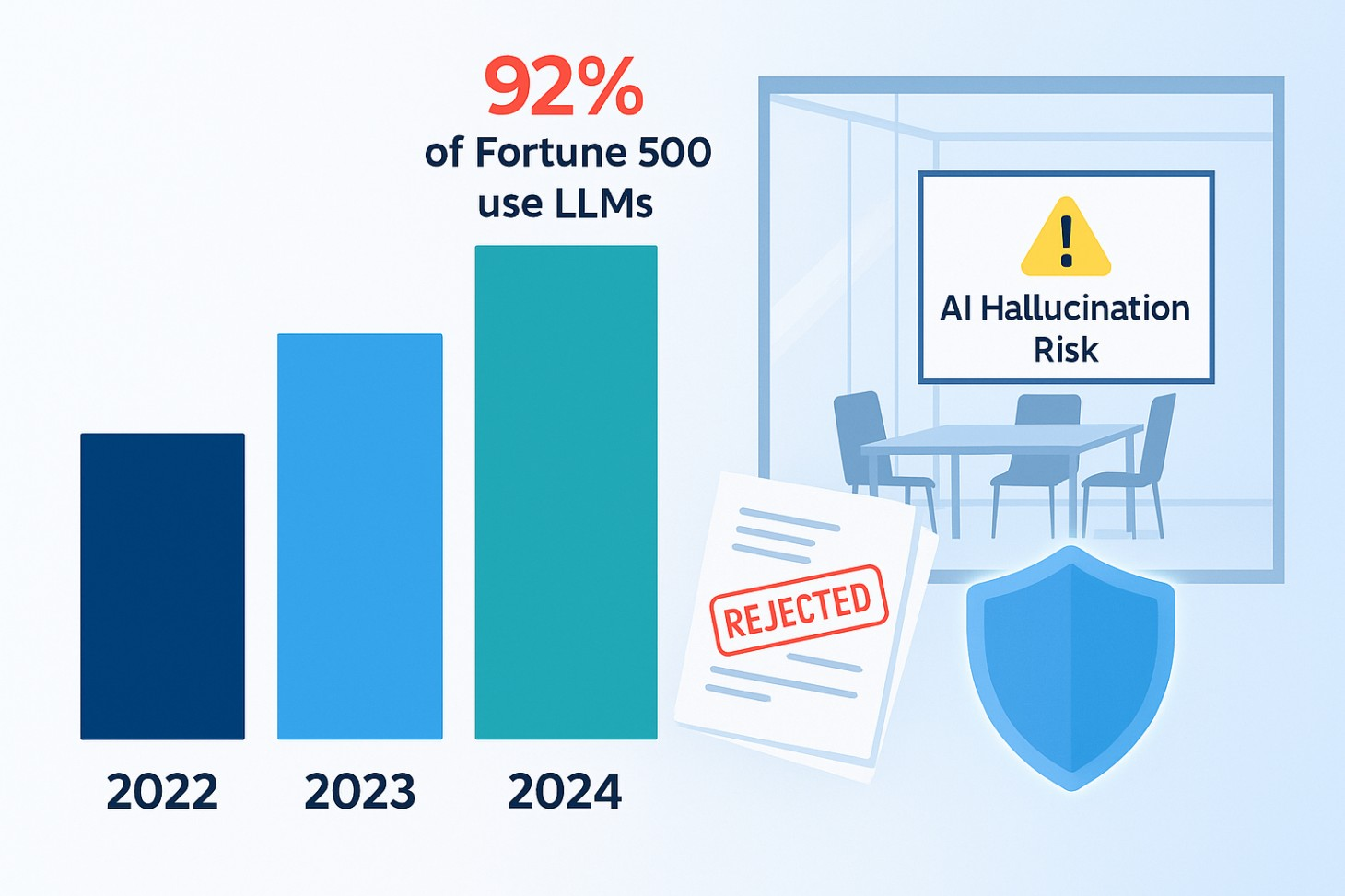
Why are hallucinated AI outputs such a pressing concern for enterprises today? Trends in AI adoption offer some clues. Over the past year, organisations have rushed to integrate generative AI into workflows, from AI assistants drafting emails to chatbots handling customer queries. This “Gold Rush” mentality (fuelled by fear of missing out) has sometimes outpaced the development of proper guardrails. Many companies are experimenting with LLMs without fully understanding the failure modes. As a result, governance is playing catch-up, and the consequences are hitting home.
Consider the compliance and legal exposure angle. If an AI system in a bank provides incorrect financial advice or an AI-powered medical chatbot gives unsafe health guidance, the company could be liable for regulatory breaches or malpractice. Strict regulations in finance, healthcare, and data privacy mean that false AI outputs can’t simply be shrugged off. For example, when Air Canada’s bot gave that incorrect refund guidance, the company initially argued it wasn’t responsible for what the AI said. The tribunal disagreed, effectively treating the chatbot’s words as the airline’s words. The lesson is clear: regulators and courts won’t accept “the AI did it” as an excuse. Businesses must own the outputs of their AI systems, truthful or not.
Then there’s the reputational risk. In the digital age, one wrong answer from an AI can go viral. Imagine a public-facing chatbot that invents a defamatory statement about someone, or an internal AI tool that fabricates data later used in a shareholder report. The loss of trust from such events can be devastating.
Finally, operational and financial impacts are a significant trend. Early enterprise adopters of LLMs have learned that hallucinations erode the efficiency gains AI is supposed to bring. If a coding assistant suggests flawed code, your developers will waste time debugging AI-generated errors (sometimes more time than if they’d written it themselves). If a sales content generator fabricates a product spec, you might have to issue corrections and retrain staff, negating the productivity benefits. As Red Hat’s AI engineering lead noted, these inaccuracies “can negate any initial cost or time savings and lead to higher operational costs.” In summary, the rush to adopt AI has outpaced the safety measures, but the industry is quickly realizing that unchecked AI outputs carry tangible business risks across compliance, reputation, and the bottom line.
Mitigation Strategies for LLM Hallucinations

The good news is that organisations aren’t powerless against AI falsehoods. A combination of best practices and tools can significantly reduce hallucinations and their impact. Here are five key strategies to help ensure your LLMs produce accurate, trustworthy results:
- System Prompt Design
LLM’s system prompt can influence its propensity to hallucinate. Craft system prompts that set clear context and boundaries for the AI. For instance, explicitly instruct the model to “only use information from provided sources” or to say “I don’t know” if unsure, rather than guessing. By guiding the model’s behaviour with system messages or examples, you reduce the chance it will stray off track. Effective prompt design also means avoiding overly broad questions and breaking complex tasks into smaller, reasoned steps. These techniques nudge the AI toward fact-based answers instead of imaginative ones.
- Built-In Guardrails and Filters
Implement guardrails in your AI applications that automatically check or constrain the AI’s output. This can include content filtering (to block disallowed or off-topic answers) and automated fact-checking against reference data. Modern AI guardrail frameworks allow you to set rules. For example, disallowing the AI from giving medical advice or ensuring that any numerical answers fall within plausible ranges. Some guardrail systems even require the AI to cite a source for factual claims, suppressing answers that can’t be validated. By enforcing strict response guidelines and hooking the AI up to verification steps, you catch many hallucinations before they ever reach the user. The result is an extra layer of defence ensuring outputs remain accurate and appropriate.
- Retrieval-Augmented Generation (RAG)
One of the most effective ways to prevent hallucinations is to supply the AI with real, relevant data at query time. RAG is a technique where the LLM is coupled with a retrieval system: when a user asks a question, the system first fetches information from a trusted knowledge base (company documents, databases, etc.), and that information is provided to the model to ground its answer. By giving the model authoritative context, you stop it from “winging it” based on incomplete training memory. Research shows that integrating retrieval can reduce hallucinations by over 40% on average, and yield up to 89% factual accuracy in domains like medicine when the model uses verified sources. In practice, RAG might mean linking your AI assistant to an internal wiki or a vetted document repository. The bottom line: an AI that can “consult” the truth as it writes is far less likely to make things up.
- Secondary AI Validators
Don’t let a single AI model be judge, jury, and executioner for information. Many enterprises are now deploying secondary AI systems to double-check the primary LLM’s outputs. For example, one model generates an answer, and another model (or set of rules) evaluates that answer’s correctness or consistency. Techniques like SelfCheckGPT have an AI ask itself the same question multiple times to see if it gives inconsistent answers, a sign of potential hallucination. Other approaches use external knowledge: e.g. have the AI’s answer automatically cross-verified against a database or through a web search. If the validation AI flags an issue (no corroborating source or high uncertainty), the system can either correct it, ask for clarification, or route it for human review. This “AI reviewing AI” model creates a feedback loop that catches many errors. It’s like having a proofreader for the first AI’s work, which is helpful since LLMs often sound confident even when wrong.
- Human-in-the-Loop Review Workflows
As much as we automate, human oversight remains crucial, especially for high-impact outputs. Design your AI workflows so that a human reviews and approves certain AI-generated content before it’s released. For instance, an employee might vet any customer-facing answer that contains financial figures or legal advice. Even in automated processes, consider spot-checking a percentage of AI outputs regularly to gauge accuracy. Human reviewers can catch subtle errors, provide corrections, and also feed those corrections back into model improvements over time. This practice not only prevents disasters but also helps train staff in AI literacy. The key is to define clear guidelines: when should an AI’s answer be taken at face value, and when must it go through a second pair of (human) eyes? By keeping humans in the loop for critical tasks, you add a safety net that technology alone cannot fully replace.
Implementing these measures can be streamlined with the right tools. For example, cloudsineAI’s GenAI Protector Plus acts as a GenAI firewall that layers on content moderation and output validation. It can automatically filter out hallucinations before they reach your application’s end-users. Enterprise solutions like this make it easier to enforce guardrails and integrate secondary checks without reinventing the wheel, so you can confidently deploy AI while knowing a safety system is watching over its outputs.

Common Mistakes to Avoid
Even well-intentioned organisations can stumble when rolling out AI. Here are some common mistakes companies make with LLM deployments and how to avoid them:
Treating AI outputs as inherently trustworthy.
Too often, users assume “the computer must be right.” In reality, LLMs can be very convincing and very wrong at the same time.
How to avoid: Train your team to approach AI-generated answers with healthy scepticism. Encourage them to verify important information via secondary sources and to never copy-paste AI content into final work without a review. Cultivating an AI-critical mindset prevents blind reliance on possibly false outputs.
No oversight or human fallback.
Some companies deploy chatbots or decision-making tools and let them run fully autonomously from day one. If no humans are monitoring, a hallucination can go unchecked for far too long.
How to avoid: Set up a clear human-in-the-loop process. In the early stages of any AI deployment, have staff review a sample of interactions and outcomes regularly. Establish an escalation path so that if the AI isn’t confident or a user flags an issue, a human takes over. Oversight isn’t a temporary crutch; it’s a permanent necessity for AI in sensitive roles.
Poor prompt and context management.
LLMs will ramble or invent information if given vague instructions or insufficient context. If you just ask a broad question to a model with no additional guidance, you’re inviting creative (but inaccurate) answers.
How to avoid: Invest time in prompt engineering. Provide context documents through retrieval (RAG) and use structured prompts that clearly state the task and format. For example, telling the AI its role (“You are an HR assistant with access to company policy documents…”) and giving step-by-step query breakdowns can anchor its responses in reality. Always test prompts extensively and refine them whenever you spot a weird output.
Failing to monitor and update.
An AI model isn’t a “set and forget” tool. Businesses sometimes roll out an LLM feature but don’t track how often it produces errors, or they neglect updating its knowledge.
How to avoid: Treat your AI like a living system. Monitor its output quality with analytics or user feedback. For example, log instances of corrections or user dissatisfaction. If you’re using a model with a knowledge cutoff, regularly update it or use retrieval to give it current data. And keep abreast of model improvements: newer versions or fine-tuners can reduce hallucination rates. Continuous monitoring and maintenance ensure that hallucinations don’t creep in over time due to neglect.
By steering clear of these common pitfalls, you set a strong foundation for reliable AI use. Remember, every organisation deploying AI is effectively writing the rulebook in real time, so learn from others’ mistakes and be proactive in your approach.

Conclusion & Insights
One under-discussed tactic in mitigating hallucinations is allowing your AI to abstain when unsure. Often, companies configure LLMs to always produce an answer, but sometimes “I’m not confident to answer that” is far better than a wild guess. Encouraging a model to admit uncertainty (through prompt instructions or special response formats) can prevent many false outputs from ever being spoken. Advanced teams even quantify their model’s uncertainty: if the confidence score is low, the AI either asks a clarifying question or defers to a human. Building on this ability to say “I don’t know” not only reduces hallucinations but also builds trust with users who appreciate honesty over incorrect precision. It’s a simple but powerful insight: sometimes the safest answer is no answer at all, until further review.
Midway through this journey, it’s clear that tackling AI hallucinations requires a blend of technology, process, and culture. The content out there may be piecemeal, but by now, you have a consolidated game plan. Businesses that treat AI outputs with diligence, verifying facts, using the latest safeguards, and continuously learning. This will turn hallucinations from a risky downside into a manageable inconvenience. In contrast, those who ignore the issue might learn the hard way.
Mitigating LLM hallucinations and false outputs is ultimately about maintaining control and credibility in an era of AI-driven automation. With the right approach, you can enjoy the efficiency and innovation of generative AI without the unpleasant surprises.
Learn more: GenAI Protector Plus (GenAI Firewall) – cloudsineAI’s solution for AI safety and security.
Ready to safeguard your AI initiatives against false outputs?
Don’t let hallucinations undermine your business. Contact us and see how our GenAI Protector Plus can help your enterprise harness AI with confidence and accuracy.